




suivant: Les tableaux
monter: Utilisation de « awk »
précédent: Syntaxe des sélecteurs
Table des matières
Index
"awk" permet l'utilisation de
variables internes. Ces variables peuvent être de type numérique ou bien
alphanumérique.
Il possède aussi un certain nombre de variables pré définies permettant de
paramètrer l'environnement de "awk" ou bien d'obtenir des informations
sur le contexte courant. Ces variables sont :
| Variable |
Description |
| FILENAME |
nom du fichier courant en entrée. |
| NR |
numéro de l'enregistrement courant. |
| NF |
nombre de champs dans l'enregistrement courant. |
| FS |
caractère séparateur de champs. |
| RS |
caractère de séparation d'enregistrements. |
$0 |
l'enregistrement courant. |
$n |
le
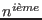 champ de l'enregistrement courant. champ de l'enregistrement courant. |
| IFS |
caractère séparateur de champs en entrée. |
| IRS |
caractère de séparation d'enregistrements en entrée. |
| OFS |
caractère séparateur de champs en sortie. |
| ORS |
caractère de séparation d'enregistrements en sortie. |
| OFMT |
format de sortie pour les chiffres. |
Exemple 15..2 :
Commande :
awk '
BEGIN {
print "Liste du fichier ", FILENAME
print
printf ("N.L.\tUID"\t|\tNom de login\n")
FS=":"
OFS="\t|\t"
}
{
printf ("%03d:\t",NR)
print $3,$1
}
' /etc/passwd
Le programme "awk" précédent s'applique au fichier "/etc/passwd",
contenant la liste des utilisateurs autorisés à se connecter au système. Ce fichier
se compose des champs suivants séparés par le caractère ":" :
- le nom de connexion ou "logname",
- le mot de passe crypté de l'utilisateur,
- son identifiant numérique unique, l'UID,
- son identifiant numérique de groupe, le GID,
- un champ de commentaires, appelé "GCOS", contenant usuellement
le prénom et le nom complet de l'utilisateur,
- son répertoire de connexion, c'est-à-dire le répertoire qu'il aura
par défaut lorsqu'il se connectera au système15.1
- le nom de l'exécutable correspondant à son interpréteur de commandes.
Pour plus de renseignements sur ce fichiers, reportez-vous à "passwd(5)".
Ce programme se décompose en deux parties :
- Le sélecteur "BEGIN" permet d'afficher un texte prélimaire
indiquant :
- la liste des utilisateurs du fichier traité (référencé par la
variable "FILENAME",
- une ligne blanche (commande "print" sans arguments),
- la première ligne du tableau généré par le programme.
L'initialisation de la variable "FS" permet de spécifier la nouvelle
valeur du séparateur de champ. Celui-ci devient le caractère ":".
L'initialisation de la variable "OFS" permet de spécifier
le nouveau format d'affichage de la commande "print". Chaque
argument de cette commande sera séparé par le caractère "|"
précédé et suivi d'une tabulation.
- Le second sélecteur ne possède aucun critère, les actions qui y sont présentes
s'appliquent à chaque enregistrement du fichier c'est-à-dire à chaque
ligne. Les deux actions présentes ont les fonctions suivantes :
- la première affiche le numéro de l'enregistrement courant sur
trois chiffres15.2 grâce à la variable "NR",
- la seconde affiche le troisième et le premier champ en utilisant
le format de sortie contenu dans la variable "OFS".
Le résultat obtenu sera donc :
liste du fichier /etc/passwd
N.L. UID | Nom de login
001: 0 | root
etc.
La définition des variables utilisateur est dynamique. Par conséquent, leur
déclaration se fait à la première utilisation et leur type s'adapte en fonction
de la valeur à laquelle elle a été initialisée. Le type d'une variable dépend de
son utilisation. Il peut être :
- numérique (virgule flottante ou entière)
- alphanumérique
Les variables sont déclarées de façon globale à tous les blocs action de toutes
les requêtes "awk". Par conséquent, une variable créée dans la requête
"BEGIN", sera accessible par toutes les requêtes "awk".
Sous-sections
suivant: Les tableaux
monter: Utilisation de « awk »
précédent: Syntaxe des sélecteurs
Table des matières
Index
baudry@esme.fr